 Pablo Carranza Vélez
Pablo Carranza Vélez- Feb 6, 2024
Graph Horizon Explained: a Proposal for the Evolution of the Protocol
Graph Horizon is a plan for serving even more web3 data needs with The Graph Network

This update was originally posted in The Graph Forum, and is syndicated below in its entirety. For feedback or discussion, please share comments on the original forum post.
If you’ve been following governance discussions or community calls within The Graph community, you may have heard about “Horizon” or “Graph Horizon”; it was mentioned in the Graph Foundation’s New Era roadmap but so far there hasn’t been a lot of detail about what it means. In short, it’s a proposal for the next iteration of The Graph as a protocol. This post explains what Horizon is from a technical and protocol design point of view.
I’m posting this as a member of the Research & Protocol team at Edge & Node - these are my views but I have done my best to capture the team’s consensus. We believe that Horizon is the best step forward for the protocol, and we’re working to evaluate different approaches to implementing it.
Graph Horizon is this team's overarching vision for where and how protocol mechanisms should evolve to realize all of the protocol’s potential. The idea for Horizon was birthed by Zac Burns, and has since evolved with input from this team and other core devs and ecosystem contributors.
As usual, we welcome feedback as we work to build consensus on the direction forward for The Graph with other members of the community. When comparing The Graph today and the proposal for Graph Horizon, I would suggest looking at the vision for the protocol as a whole rather than the individual differences in isolation, as the system presented here works differently than the current protocol at many levels, so the differences make a lot more sense in combination and many are interrelated.
So what is Graph Horizon?
Graph Horizon is a vision for the next evolution of The Graph, rethinking mechanisms from first principles. In the following sections we will discuss what makes Horizon different from The Graph as it is today, as if it were a completely new protocol. We’ll discuss how to get there later, but the end state we’re aiming for is a more flexible, efficient and censorship-resistant protocol that can scale to organize all of the world’s public data and information.
In simple terms, Graph Horizon is about iterating upon the existing protocol to address things we’ve learned since the protocol launched, and implement improvements we’ve heard suggested in conversations with many users and contributors, to ensure The Graph fulfills its mission and remains core and reliable infrastructure for web3.
Summary of the differences between Graph Horizon and the current protocol
Depending on the community’s consensus, as we’ll discuss later in this post, Horizon can either be deployed as a new protocol in parallel to the current one, or as a set of updates to the existing protocol.
This summary shows the main differences between The Graph today and what we’re proposing. The rest of this post will explain the reasons for these, so I would kindly ask folks that want to engage in the discussion to read the rest of the post in full first.
- An immutable (or limited-upgradeability) generalized Staking contract, which allows permissionless addition of data services and a more modular protocol, instead of a monolithic protocol which only supports subgraphs with explicitly approved features.
- Measurable and increased economic security where allocated stake accurately represents slashable stake, using slashable delegation. This allows for a system with more transparent economic security.
- A fully permissionless and more censorship-resistant way to ensure subgraphs are indexed through indexing fees (a model applicable to all data services), that does not rely on Indexing Rewards (even if those remain unchanged at this time).
- Decentralized, configurable arbitrators or verifiers instead of the current governance-selected arbitrator.
- Reduced surface area for governance, and introducing modular / custom governance at the data service level.
- A core mechanism that doesn’t need any taxes or fees, but allows data services to implement them as desired.
At the core, Staking
Horizon is a more modular protocol where new data services like Firehose, Substreams, SQL or LLM queries (to name a few potential examples) coexist with the subgraphs we know and love.
Horizon presents Staking as a generic primitive upon which arbitrary data services can be built. The core idea is simple: to provide a data service, a Service Provider (i.e. an Indexer - I will use Indexer and Provider interchangeably below) needs to stake some GRT, and risk being slashed if they act maliciously or break any protocol rules. This is the basis by which a data consumer can trust any data from the provider. This process will generally follow this pattern:
- If necessary, the Provider stakes GRT to guarantee a non-malicious service before starting, so that they can be slashed even if they don’t collect any fees.
- The Provider serves data, and collects receipts or other evidence that will allow them to collect fees.
- The Provider stakes GRT proportionally to the fees they intend to collect, then collects the fees and locks these GRT for a dispute period.
- A verifier can slash the Provider according to a set of rules, up to the stake amount deposited for the specific service that is being disputed.
People familiar with the current protocol might see a similarity with the concept of “allocations”, where Indexers set out a specific amount of staked GRT to serve a particular subgraph. Horizon generalizes this concept so these deposits can work at the data service level: for instance, a single deposit/allocation could provide stake for the Firehose service, or for all subgraphs (assuming a different subgraph data service), or for all LLM queries served by a Provider, etc. Each data service can define the rules for what needs to be staked for which kind of service, the relationship between staked GRT and collected fees (which we can call a “stake-to-fees ratio”), and the length of the dispute period.
However, unlike the current form of allocations, up to the full allocation can be slashed depending on the type of fault, as defined in the data service contract. In an improved subgraph query service, for instance, the slash amount could be a multiple of the query fee paid for the disputed query, instead of the constant 2.5% of total stake used today.
I’ll refer to these stake deposits as “allocations” going forward, but it’s important to note they have these differences with the allocations in the current protocol.
Permissionless composability
As hinted above, Horizon introduces permissionless composability by allowing arbitrary data services to make use of the Staking mechanism. Whenever an allocation is made, the Service Provider can specify an arbitrary address as the “verifier” that has the authority to lock and slash the deposit. The verifier will generally be a data service contract, for instance, a SubgraphQueryService contract could implement the logic for disputes that we have in the current protocol, with an arbitrator role that can decide when a query response is disputed. Other data services may use optimistic fault proofs or even zero-knowledge proofs to determine whether a Provider should be slashed (and we believe all data services should strive towards automated dispute mechanisms like this).
Each data service can define its own stake requirements, fee structure, and rules of operation. They can have their own governance or be fully immutable. They could even use their own token as long as they adopt the staking mechanism using GRT. This permissionless core allows anyone to build on top of The Graph and should allow a Cambrian explosion of data service models and innovation.
This permissionlessness requires trust in the stability of the underlying layer. For this reason, we propose that the Staking contract must be non-upgradeable or have some limitations on how it can be upgraded (e.g. a timelock).
Decentralized arbitration
The ability to specify a verifier at the data service level means that data services that require human arbitration can explore many ways for this arbitration to work. The simplest form is to have a single arbitrator address selected by governance (as in the current protocol), where that address could be a multisig or a DAO; but some data services could use other models or even allow the Provider to select the arbitrator when making an allocation, or agree to it with a data consumer when starting to provide a service. This is similar to selecting a jurisdiction or arbitrator for a contract in the legal system.
Horizon can also allow data services to provide incentives for the arbitrator, by allowing the verifier to take up to a specified amount of the slashed funds and redirect them somewhere else. This would allow paying a Fisherman, investigator and/or an arbitrator from either the slashed funds or a bond posted by whoever raised the dispute. This could foster an ecosystem where many arbitrators compete and build a reputation of providing fair resolution to data validity disputes.
Increased economic security
As mentioned above, one of the key points in Horizon is making the full stake allocation slashable in the case of a fault. This doesn’t mean that the full allocation will be slashed for a single fault - it simply means that the data service is allowed to slash up to this amount, but each data service will define the rules for how much gets slashed for each fault. In general, we expect data services to specify a “stake-to-fees ratio”, such that collecting a certain amount of fees requires a certain amount of stake (e.g. multiplying by a 1,000x factor) or even to make this configurable by users. This will give data consumers a much clearer and more predictable measure of how much is at stake when they are querying data from The Graph, which is an important requirement when querying from a decentralized protocol with anonymous Indexers / Service Providers. As more data services are added with each potentially having their own base of anonymous Service Providers, it will become more important for data consumers to have the necessary assurance that the data is correct and that malicious behavior is deterred.
Using the allocation as the specific amount that can be slashed ensures the stake is not leveraged, which would allow a malicious provider to perform multiple simultaneous attacks without risking any more funds. This also makes economic security easier to measure, as a data consumer can be assured that the specific stake-to-fees ratio will be enforceable at the time of making a dispute.
A new approach to delegation
This understanding of economic security introduces another important requirement: since service providers allocate their own stake together with delegated stake, for delegated stake to contribute more meaningfully to economic security, it must be slashable as well. This would be a departure from the current mechanism, but matches the behavior in most other protocols, and will make the Delegator role much more important and impactful to the protocol.
It is important to note that the Indexer’s self-stake would always be slashed first, so the actual risk to Delegators would be somewhat mitigated: an Indexer would have to act so maliciously that their whole self-stake would have to be slashed before any of the Delegators’ tokens are slashed. In most data services, this should require sending lots of malicious data. So while an important deterrent, it is to be expected that minimal vetting of the Service Providers would be sufficient, much like it is today.
Besides this important change, the interface to stake and allocate to a data service could be extended to allow other forms of delegation to be built on top. One example is Tenderize’s liquid delegation service which already works with the current protocol, but if a contract can stake and allocate on behalf of an Indexer, there is the possibility of building delegation pools that Indexers can use to provide collateral for a specific short period, e.g. to collect a specific fee voucher. This could open up another avenue for innovation where developers could find new ways to use GRT to support the protocol.
Additionally, because allocations are locked for specific dispute periods, any un-allocated delegation could be immediately withdrawable, so the current model where withdrawing a delegation takes 28 days could be replaced with a more dynamic queue mechanism based on idle delegation and tokens freed when an allocation is closed. Moreover, since slashable delegation removes some potential attack vectors, there is no need for a delegation tax in this mechanism.
Improved censorship-resistance
The Indexing Rewards mechanism, while providing the basis for the current decentralized protocol, necessarily relies on the Subgraph Availability Oracle to ensure only valid subgraphs with supported features that are approved by governance can receive rewards. This allows the current decentralized protocol to provide rewards to Indexers which has helped bootstrap the Network to its high quality of service. But it also means there is an opportunity for further decentralization here and creates other challenges in ensuring the oracle is run transparently and can keep up with any new failure modes or attacks. In general, reducing the reliance on oracles can make the protocol more censorship-resistant, making it resilient even in the unlikely case of compromised governance. Moreover, the current curation mechanism can become unpredictable if large amounts of curation are added or moved suddenly, potentially driving Indexers away from a subgraph. While these theoretical issues haven’t significantly affected any subgraphs so far, they will become more important to address as The Graph scales to more subgraphs and more data services.
Unfortunately, it seems that there are no straightforward solutions to these challenges as long as Indexing Rewards are the main mechanism to get subgraphs indexed (or for other data services to bootstrap service). The research team has consistently hit a dead end when trying to find a permissionless, non-gameable mechanism to distribute rewards for “useful work”, and has even found some interesting impossibility results that seem to indicate that the challenge cannot be solved under the specific constraints that we face.
This leads to the most straightforward conclusion: for a subgraph to be indexed, the best way to go about this is that someone should pay for it. This proposal, “Indexing Fees”, has already been presented in GIP-0058, and while it doesn’t necessarily depend on Horizon, it could be a prime example of a “data service” built with Horizon’s Staking mechanism. Services like this can have very strong censorship-resistance.
For the moment, this mechanism would work in parallel to Indexing Rewards. Similar mechanisms could also be built as part of other data services so that any pre-requisite work to serve data could be supported even if the data service doesn’t go through any governance process to receive Indexing Rewards.
Side note on the dilemma of consumer choice
Since I’ve mentioned Indexing Fees, I would like to take a moment to comment on one of the main concerns that had been raised by Indexers about this proposal: that if users are able to choose individual Indexers, they could all end up choosing one big centralized Indexer, which could drive others out of the market. I think this is a valid concern that is worth addressing. I will list below several arguments for why I’m convinced this will not be happening, supported by the Research team’s work and how we’re thinking of implementing this. The Research team’s conclusion, additionally, is that competition for Indexing Fees is the best possible way to ensure Indexers are compensated fairly and predictably for their work, while ensuring that data consumers receive reliable service at predictable prices - you can learn more in this Indexer Office Hours presentation.
- To begin with, the “choice” will be possible at the protocol level, but there is in my opinion no good reason to expose an “Indexer menu” in the Studio UI, I don’t think core developers should build it, and I would expect most gateways would prefer to provide automated Indexer selection algorithms instead. As far as I know, most users don’t care about which particular Indexers are indexing their subgraph, and generally want a simplified experience when interacting with The Graph. Gateways will be much better suited to choose Indexers than data consumers, as they will have aggregated data about Indexer Quality of Service (QoS) and other relevant parameters. The main abstraction presented to data consumers should be a “network” of decentralized data services rather than a “marketplace” of individual indexers.
- In addition, Gateways that want to provide good QoS to their users would be encouraged to load balance across many Indexers and provide redundancy. They would also be encouraged to incorporate various parameters in Indexer selection: cost is a factor of course, but weighing stake and delegation is important to provide Sybil resistance, weighing past QoS will be important as well, and incorporating some randomness can help a lot in reducing the chances of a Sybil exploiting the mechanism. All of this favors a broad base of Indexers getting Indexing Fees rather than one big whale. Moreover, choosing only one Indexer per subgraph exposes the data consumer to outages, and choosing several is the best way to provide top-notch uptime and QoS. Consequently, except for very budget-limited subgraphs I would expect most devs would pay for some redundancy and in doing so favor decentralization.
- In the latest version of GIP-0058, Indexing Rewards will still flow to Indexers that want to index subgraphs even without indexing fees, so the current way for Indexers to get paid directly from the protocol will remain as it is. We’re still working on proposals for the future of protocol issuance, but supporting our Indexers will of course be a main concern in any upcoming proposal.
- Finally, it is worth noting that data consumer choice is already possible: data consumers can already choose to use centralized indexing services instead of The Graph. Providing this internal competition inside The Graph is the way to ensure that the protocol remains the best way to get access to subgraphs, and I strongly believe it will be so because of its decentralized nature, the access to multiple Indexers providing superior QoS, and its verifiability and economic security.
If Indexers still have concerns after reading this, I would love to chat to discuss how to mitigate them (I plan to join some upcoming Indexer Office Hours calls as usual).
More efficient interactions
The permissionless design in Horizon has no need for any token burn mechanisms, taxes, or other protocol fees at the core protocol level. In the current protocol, these taxes and fees are in place to prevent attacks that generally have to do with redirecting Indexing Rewards to a malicious Indexer. Graph Horizon does not, for the time being, propose an issuance mechanism and therefore does not have these risks, obviating any need for taxes. Moreover, Horizon provides an alternative to rebates, which potentially burn some of the fees of an under-staked Indexer, by allowing the Indexer to stake exactly the required amount before collecting fees.
Ultimately, each data service developer can choose whether to incorporate any fees or taxes, if they make sense for that particular service. They could keep a rebate formula or adopt the proposed stake-to-fees ratio approach. They could add burning mechanisms or charge a service fee to fund development of the data service. But the core protocol does not need to extract any of these.
This additional efficiency, coupled with the other changes that improve competition on price, quality and innovation, should result in better products at lower prices for data consumers.
At the same time, this ensures that Service Providers can receive most if not all of the fees they accrue, while it incentivizes subgraph developers and people developing other data services to optimize them. This reduces costs for Service Providers, which in turn fosters decentralization by reducing barriers to entry.
There is, of course, the exception of the existing subgraphs data service that will still have the current Indexing Rewards mechanism based on issuance and curation. This will still require keeping curation fees and some protocol taxes until we find an alternative approach for issuance.
Two ways to get there: brownfield or greenfield
So far we’ve discussed Horizon as if it were a completely new protocol. In practice, we are still figuring out if the best path forward is to deploy a new protocol (what I will call “greenfield Horizon”) in parallel to the existing one, and eventually get everyone to use it, or to make the current protocol evolve into Horizon (what I will call “brownfield Horizon”) by means of GIPs and the support of the community and Council to perform contract upgrades at each step.
On the one hand, the brownfield approach would give us a more straightforward way to improve the protocol without needing a migration later. On the other hand, we can start working on the greenfield approach without affecting the current protocol, and learn through its usage and community feedback - though participants would eventually need to move to the new protocol to take advantage of the benefits, which also involves the challenge of running two protocols in parallel like we’ve been doing with L1 and L2. Rewards flowing to the old protocol would keep things running in the old ways, until the Council decides to redirect them somewhere else (for which we’ll need a future governance proposal).
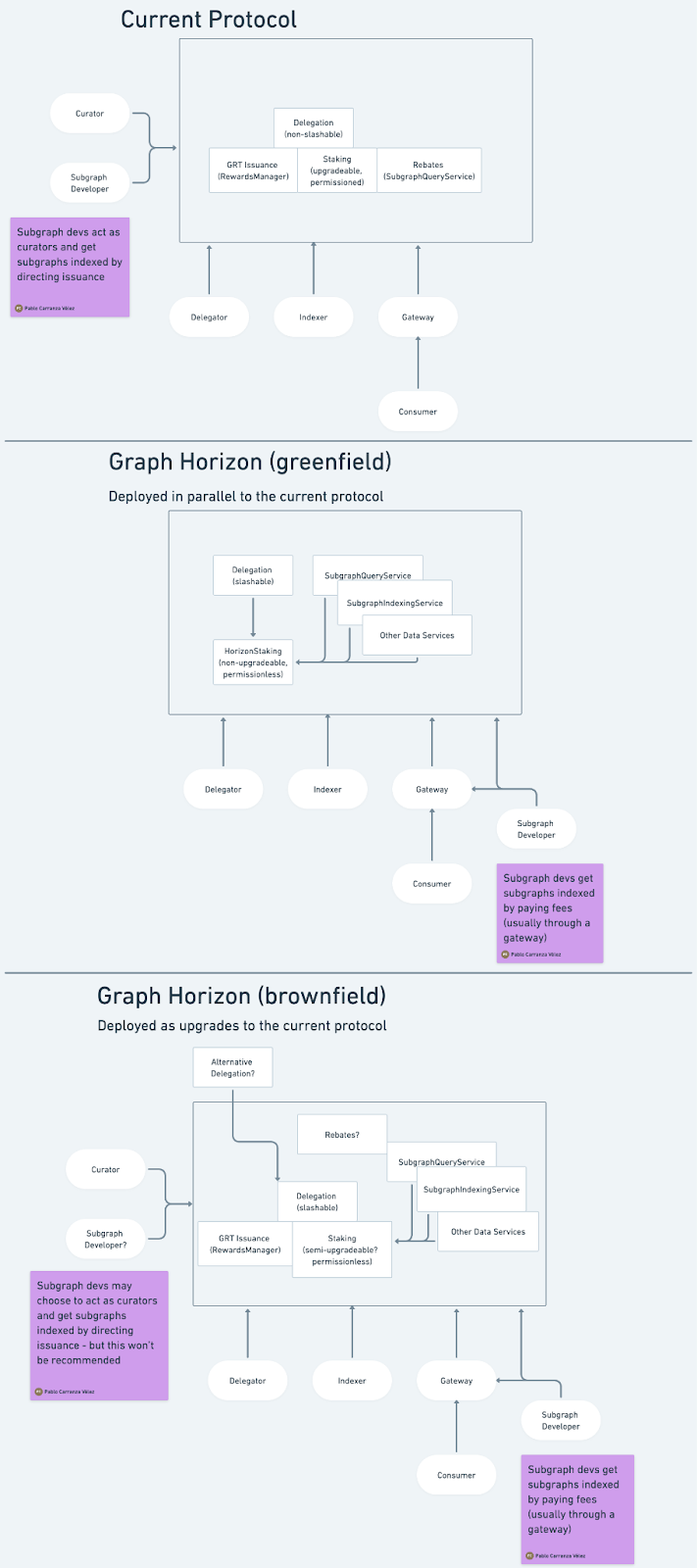
What about rewards and Curation?
As I mentioned, we are not proposing any changes to Indexing Rewards and curation at this time. In the greenfield case, the new protocol would coexist with the old one, that would be unchanged. In the brownfield case, the changes to support permissionless data services and the other improvements mentioned above can be applied while keeping the Indexing Rewards mechanism untouched.
The conclusions from our team’s research, however, are quite clear: the current rewards model, while it has helped us bootstrap a great network of Indexers, will need to change if we want The Graph to realize its full potential. Curation is not very effective at driving rewards to the most used subgraphs, the mechanism can lead to attempts to harvest rewards without doing useful work, and there is no way to make it work without oracles. If anyone wants to dive into the details of this, the Research & Protocol team at Edge & Node would be happy to discuss or share more details.
A corollary (and this is a more personal opinion) is that we need to expand the design space. Horizon gives us a core protocol that is not dependent on rewards (as indexing fees provides a way to get subgraphs indexed permissionlessly), so we can start exploring ways of replacing the issuance mechanism with one that works outside the core protocol in a way that benefits the growth of the network, favors decentralization, and rewards useful work. There will surely be a place for some form of curation there. I have some ideas, but we can explore them in a different thread.
The current Horizon design, however, is solid enough by itself that it does not need issuance to function, as long as there is demand for the data services built on top of it. This allows us to move forward while we figure out what we want to do with issuance, keeping the current mechanism in place so that the Indexer community can keep thriving. While we do this, and with the Sunrise of Decentralized Data, we pave the way for query fees to become much more prominent than issuance, which will also make it easier to change the mechanism in the future.
Summary of the areas improved by Graph Horizon
Horizon proposes a different protocol for The Graph, and in doing so solves many challenges, both practical and theoretical, that exist in the current protocol:
| Challenge | Solution |
|---|---|
| A monolithic protocol is hard to extend to add more data services, especially with each addition requiring going through the GIP process, and imposes unnecessary restrictions by making addition of new services permissioned by governance. | Horizon addresses this by allowing data services to be permissionlessly added as a field in allocations (even if the Council keeps rewards for only a permissioned subset) |
| While the current protocol’s mechanism for allocations would allow new data services to be implemented, it provides a limited API for doing so. There is no flexibility to use different arbitration mechanisms, dispute periods, fee distribution logic, or include any additional data for allocations other than a subgraph deployment ID. | Horizon addresses this by making allocations or stake deposits a generic interface for arbitrary data services with permissionless configuration of dispute periods, arbitration, and any other relevant parameters. |
| Delegation does not contribute to economic security to its full potential: it may act as a signal for how trustworthy an Indexer is, but it does not increase protection for data consumers in terms of slashable GRT. For arbitrary data services to provide effective economic security, each allocation should be fully comprised of slashable stake. | Horizon addresses this by making delegated stake slashable (only if all of the Indexer’s self-stake has been already slashed). |
| Indexing Rewards involve many places where subgraph indexing relies on governance more than it should (Subgraph Availability Oracle, Epoch Block Oracle, issuance configuration, arbitration), so having them as the only mechanism to get a subgraph indexed means there is room to improve on censorship resistance. | Horizon addresses this by introducing indexing fees as a way to get a subgraph indexed (even if rewards are not enabled for the subgraph), improving censorship-resistance. |
| While the value of total indexing rewards would vary with network growth, they can eventually be insufficient to cover new subgraphs, let alone new data services. There could be a point where new subgraphs or data services cannot be bootstrapped without reducing QoS for others. | Horizon addresses this by introducing indexing fees as a way to get a subgraph indexed (even if rewards are insufficient). |
| Indexing Rewards based on curation to get subgraphs indexed provides no predictability for data consumers or Indexers, as actions by other actors may affect the profitability of indexing a subgraph. | Horizon addresses this by introducing indexing fees as a way to get a subgraph indexed (even if rewards are insufficient). |
| Based on research results, there is no way to produce a fully permissionless mechanism to reward Indexing that is Sybil-resistant and not gameable - therefore we have no way to make a fully permissionless protocol unless we move rewards outside of the core flow. | Horizon addresses this by introducing indexing fees as a way to get a subgraph indexed (even if rewards are denied) which opens a path to plug issuance as an external way to incentivize desired outcomes (e.g. create indexing fees agreements, or subsidize actors directly). |
| The current mechanisms for rewards and rebates redirect a large percentage of data-consumer-to-Indexer payments to other places (Curators, taxes), which in the long run can mean unsustainable prices or giving advantage to centralized competitors. | Horizon addresses this by adding an alternative to rebates (requiring a specific amount of stake to collect a specific amount of fees), and by allowing permissionless data services to configure variable values for Curator fees, taxes, etc., as desired by the data service developer. |
| The core Staking contract being instantly upgradeable requires placing more trust than necessary on the Council. | Horizon addresses this by either deploying a new non-upgradeable Staking contract, or removing/limiting upgradeability of the Staking contract. |
| Even if gateways were to abstract the complexities of the protocol through subscriptions, building these subscriptions on top of complex mechanisms that have some inefficiencies adds costs to the subscriptions and could make The Graph less competitive. | Horizon addresses this by enabling clear and transparent pricing on indexing fees (in parallel to rewards, until rewards change). |
There are some other challenges that may be solved depending on how we implement Horizon (there are other tradeoffs to be discussed):
| Challenge | Potential solution |
|---|---|
| Per-subgraph allocations are expensive. | If we change to deposits/allocations at the data service level, Horizon would fix this as there’d be no need for subgraph-specific ongoing transactions. |
| Choosing what Indexer to delegate to can be hard. | If we deploy a new delegation mechanism based on pools, then Horizon would fix this by allowing Delegators to choose a pool that delegates to many Indexers. Alternatively, this can be solved extra-protocol by liquid delegation providers like Tenderize. |
So what happens next?
We’d very much like to hear from you! We’ll take feedback in this forum thread and we will be joining community calls to discuss the proposal and answer any questions or concerns. We would also like to discuss this with the Council soon, to understand what they think of the proposed vision and their stance on the brownfield / greenfield approaches. Depending on the reactions to this forum post and the other ongoing communications about Horizon, I imagine the Council may call for a community Snapshot vote. If there is consensus for a brownfield Horizon, we will start posting the GIPs for each of the specific changes to convert the protocol into Graph Horizon. If there is no clear consensus or there is more support for the greenfield approach, we can keep working on the greenfield Horizon, and hopefully prove its value to everybody over time, while we incorporate the feedback and work to address concerns.
We’re also very eager to start and keep building. We have already done some initial work on the greenfield version of the contracts, but there’s still a lot of work to do to get it ready for audit and deployment. We have some internal docs on what we think the contracts should look like and what GIPs would need to be approved if we were to take the brownfield approach. We’d like to keep working on both approaches in parallel until we have a better understanding of where the community and the Council stand. We also want to start implementing some data services (for example, indexing fees) to ensure the interfaces work as intended, and work with potential data service developers to ensure the interfaces meet their needs. No matter which path we take, we expect this will take a year or more to build, audit and test, and we will iterate on the design as we make progress. Community members are welcome to reach out if they want to participate and contribute to the implementation - there will be more activity in this forum and we’ll be joining community calls regularly.
Hopefully this post, together with Zac’s recent GRTiQ podcast can show other community members why we think this is the best path forward for the protocol and get everyone on board to make this happen.
Subscribe to our newsletter for the best of web3
Stay on top of the latest web3 news with a fresh cup of web3 Tea delivered right to your inbox. Web3 Tea is a bi-weekly round-up of web3 developments, macro observations, and profound tweets.
Stay stimulated with web3 Tea, whether you're a web3 beginner or expert!